
Hay muchas empresas que dentro de su proceso de adopción se han enfocado en encontrar casos de uso.
El foco en casos de éxito tiene todo el sentido del mundo. Si un equipo encuentra una aplicación útil, lo comparte con el resto. Si alguien consigue ahorrar tiempo con una tarea, se convierte en ejemplo. Si un área logra una mejora visible, se presenta como referencia para que otros puedan replicarla.
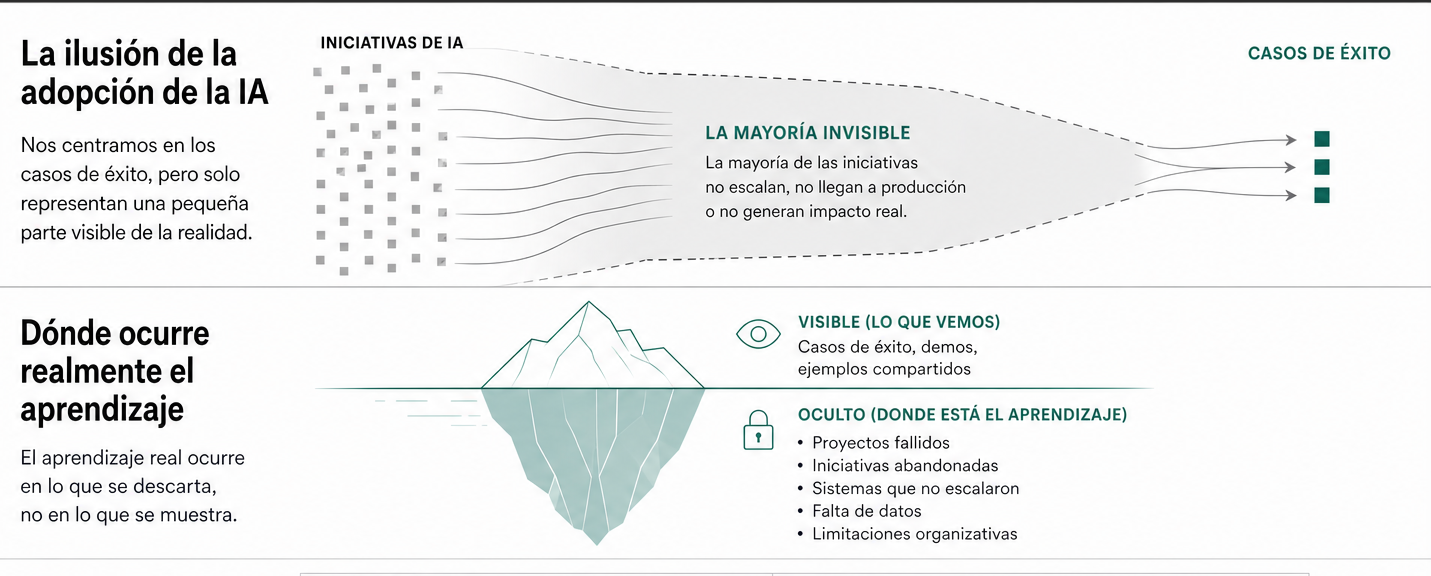
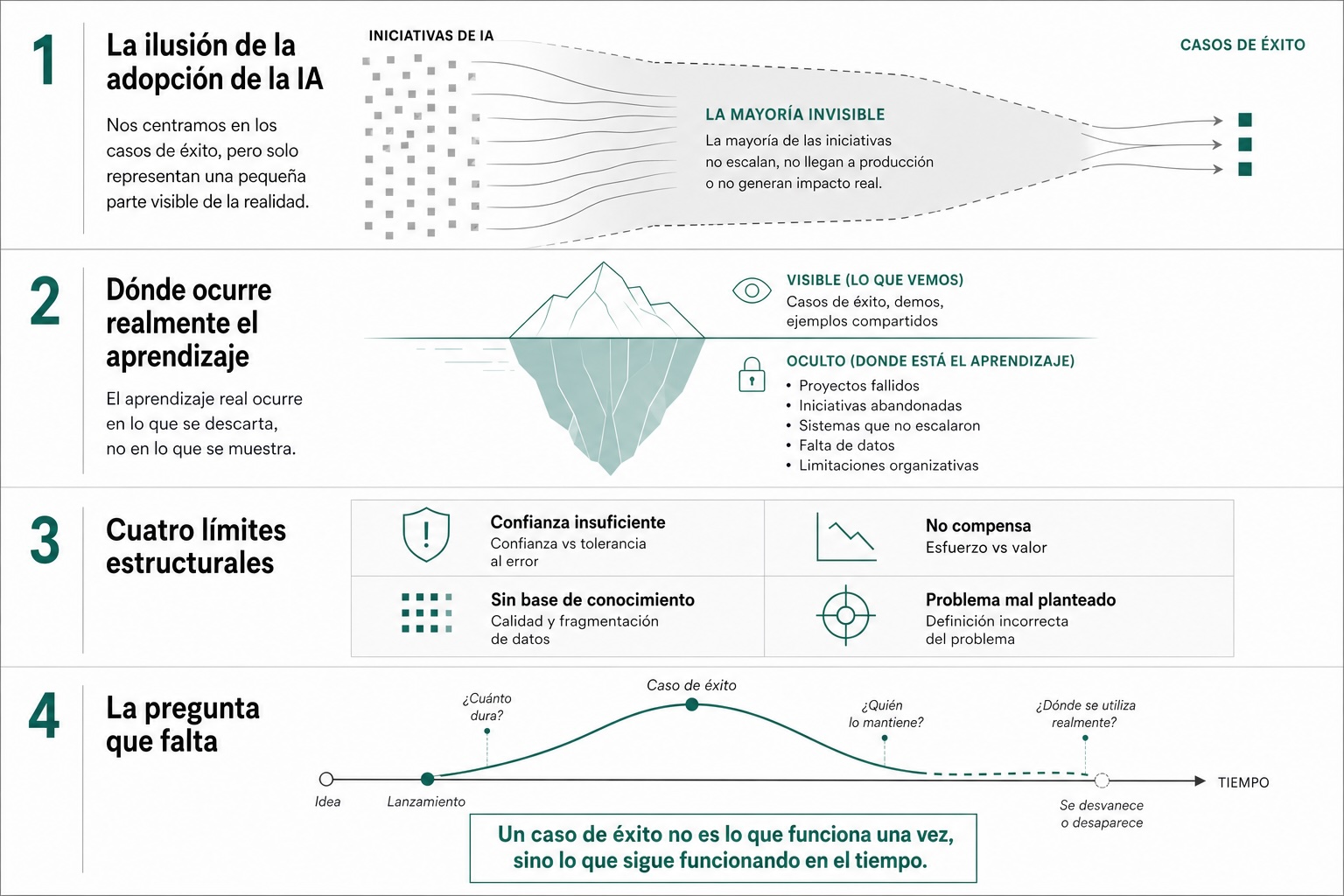
El problema con los casos de éxito es que deja fuera una parte de la realidad del proceso de adopción de la IA.
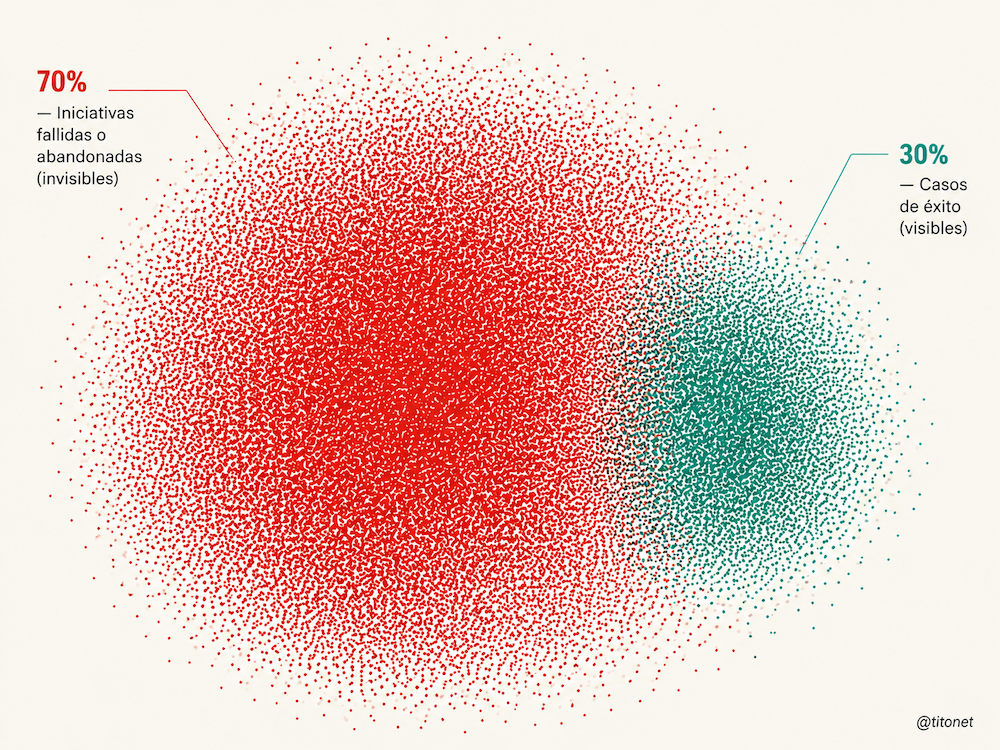
Distintos análisis de consultoras (Gartner y McKinsey) llevan años situando en una horquilla aproximada del 70% al 85% el porcentaje de iniciativas de IA que no llegan a producción, no escalan o no generan impacto real en negocio. La cifra concreta puede variar según el estudio, la definición de fracaso y el tipo de proyecto, pero hay algo que me interesa destacar. Una parte muy importante de lo que se intenta con IA no acaba convirtiéndose en valor real.
Esto no significa que todo sea un desastre, simplemente es parte del proceso de aprendizaje. Se aprende de los errores dice el refranero.
Además, hay otro detalle a destacar. Centrarse solo en los casos de éxito construye una realidad sesgada. Miramos los proyectos que han salido bien, buscamos los elementos que explican su éxito y asumimos que basta con repetirlos en otros contextos. Que haya funcionado una vez no garantiza que funcione en otro contexto.
No estamos viendo todo lo que quedó por el camino. No vemos los intentos que parecían prometedores y se abandonaron. Si no compartes los errores, lo habitual es que otras áreas y departamentos caerán en los mismos errores. Porque con la IA todos estamos explorando y buscando los límites.
Por eso convendría añadir a los casos de éxito, el registro de lo que no ha funcionado. No como una colección de fracasos para repartir culpas o responsabilidades, sino como una fuente de información sobre hasta dónde llega realmente la tecnología, los datos y la propia organización.
Los casos de fracaso y su clasificación
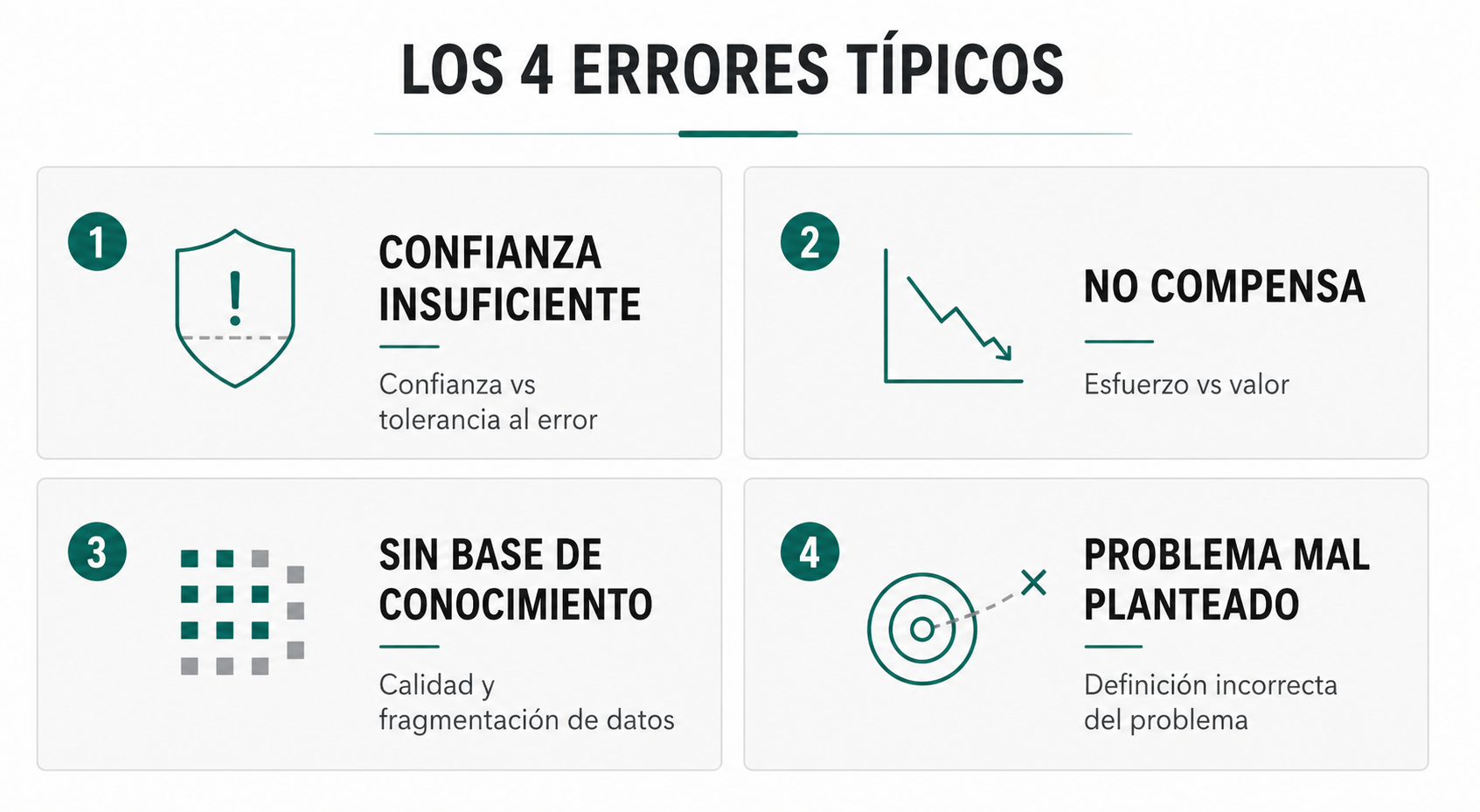
La palabra fracaso, además, conviene usarla con cuidado. Si quieres que el error sirva para algo, necesitas nombrarlo bien. Mientras todo sea “no ha funcionado”, no hay aprendizaje. Deberíamos clasificar los casos de uso que no han funcionado. Os propongo la siguiente clasificación:
#ERROR TÍPICO 1
La precisión no es suficiente para confiar en el resultado
Este es uno de los casos más habituales. El sistema responde, genera una salida razonable e incluso puede impresionar en una primera prueba, pero cuando se intenta utilizar de manera continuada aparecen errores que impiden integrarlo en un proceso real.
No hablamos de que falle siempre. Muchas veces falla poco. Y ahí está el problema. En determinados procesos, fallar poco sigue siendo demasiado. Una cosa es utilizar IA para preparar un primer borrador, explorar ideas o resumir documentación interna. otra diferente es para un proceso crítico.
Un ejemplo sencillo: un sistema que acierta el 92% es completamente inviable en atención al cliente. no puedes fallar el 8% de las veces.
En estos casos, el aprendizaje no es “la IA no sirve para esto”. Es entender que, con los datos actuales y las herramientas actuales, el resultado no alcanza el umbral de confianza necesario. Por eso guardar este caso es importante por que tanto datos como herramientas evolucionan en el tiempo.
#ERROR TÍPICO 2
El resultado es útil, pero no compensa
Hay proyectos que técnicamente funcionan y aun así no tienen sentido. La demo sale bien y todo parece indicar que el caso debería avanzar. El problema aparece cuando se calcula el esfuerzo real que exige mantenerlo.
Puede requerir demasiada supervisión humana, demasiada preparación previa, demasiada integración con sistemas existentes o demasiada formación para el equipo. El resultado es útil, pero el coste total de hacerlo funcionar supera el valor que genera.
Aquí el límite no está en la capacidad de la IA, sino en la relación entre esfuerzo y retorno.
Un ejemplo claro: un sistema que genera propuestas comerciales personalizadas funciona bien en la demo, pero para que sea usable hay que revisar cada salida, ajustar inputs manualmente y conectar tres sistemas internos. El equipo acaba dedicando más tiempo a mantener el sistema que a utilizarlo. El resultado es correcto, pero no compensa.
#ERROR TÍPICO 3
No hay base de conocimiento suficiente
Muchas iniciativas fracasan antes de empezar, aunque se descubra más tarde. El caso parece interesante, la herramienta parece capaz y el equipo tiene una expectativa clara. Después aparece la realidad: los datos están dispersos, los documentos no están actualizados, la información relevante vive en correos, presentaciones antiguas, carpetas compartidas y en la cabeza de personas que llevan años resolviendo cosas sin documentarlas.
En ese punto, la IA no está fallando. Está haciendo visible cómo está organizado —o desorganizado— el conocimiento.
Un ejemplo típico: se intenta construir un asistente interno para responder preguntas de empleados, pero la información relevante está repartida entre PDFs antiguos, wikis sin actualizar y correos. El sistema responde, pero lo hace con información incompleta o contradictoria. El problema no es la IA, es la base de conocimiento.
#ERROR TÍPICO 4
El caso estaba mal planteado desde el inicio
A veces el fallo no está en el modelo, ni en los datos, ni en la herramienta. Está en la pregunta de partida. Se intenta aplicar IA a una tarea poco relevante, a un proceso que nadie necesita mejorar o a una idea demasiado vaga para convertirse en algo operativo.
Aquí no falla la IA. Falla el encuadre.
Un ejemplo frecuente: se plantea automatizar con IA la redacción de informes que en realidad nadie lee o que no tienen impacto en ninguna decisión. El sistema puede funcionar técnicamente, pero está resolviendo un problema que no merece ser optimizado.
Clasificar estos errores permite entender algo que los casos de éxito no enseñan bien. Algunos límites dependen de la tecnología y pueden cambiar en pocos meses. Otros dependen de los datos y requieren trabajo interno. Otros dependen de la organización y no se resolverán por mucho que mejore el modelo.
Esa diferencia es la que permite entender que no todo lo que no funciona hoy es un mal caso. Muchas veces es un caso adelantado. Y si no lo registras bien, cuando vuelva a ser viable, ni siquiera sabrás que ya pasaste por ahí.
NOTA MENTAL: Otro día hablaremos de los casos de uso de éxito. ¿Cuánto duran realmente los casos de éxito?. En muchas organizaciones ni siquiera se sabe si siguen vivos seis meses después, quién los mantiene o en qué momento del trabajo real se utilizan. Y ahí es donde se separa lo que funciona de verdad de lo que solo funcionó una vez.
Espero que os haya gustado.


